
In today’s digital age, data is not only common but also one of the most crucial elements driving innovation in fields ranging from business and healthcare to sports and science. Without examining, observing, experimenting, and studying the vast amounts of data available to us, consistent innovation would be impossible. Data processing has become an indispensable part of modern life. For instance, in the finance sector alone, studies estimate that around 1.5 quintillion (10^16) data points are processed worldwide on a daily basis, highlighting the immense importance of data in our daily lives.
Processing large datasets can be a daunting task, but thanks to advancements in technology, tools were introduced in the early 2000s to optimize their processing. In particular, Spring Batch, introduced in 2008, has been instrumental in the development of robust batch applications for handling massive amounts of data
Spring Batch
Spring Batch is given an extension module of the spring framework which is developed by the Pivotal Team. Spring Batch is intended to work in conjunction with a scheduler rather than replace a scheduler. The basic job of the applications created is to process huge amounts of data batch by batch by reading from one source, processing data with required changes and writing data to the defined destination.
Batch processing is commonly used in sectors such as Banking, E-commerce, Insurance, Telecommunications etc. It involves the execution of a set of instructions on a specific set of records at a scheduled time on a regular basis.
Spring batch is designed to handle large volumes of data efficiently, making it suitable for processing tasks that require the processing of large datasets. It can be integrated with various data sources and processing technologies such as Hadoop, JDBC and JMS.
Data Processing
Speaking of it, huge amounts of data is being processed in banks daily, especially after the introduction of services like NEFT & UPI. Other than that, data processing is essential for various tasks such as Bank loan information, generating account statements, and handling account reconciliation. Sprint batch can be used to collect Bank Loan information, find defaulters and send notifications to them.
A common use case for Spring Batch is to import data from a CSV file into a database. A CSV (comma-separated values) file is a text file that has a specific format that allows data to be saved in a table-structured format. Suppose a bank receives a daily transaction report from an external vendor in CSV format. The bank needs to import this data into its core banking database, which contains customer account information and transaction data.
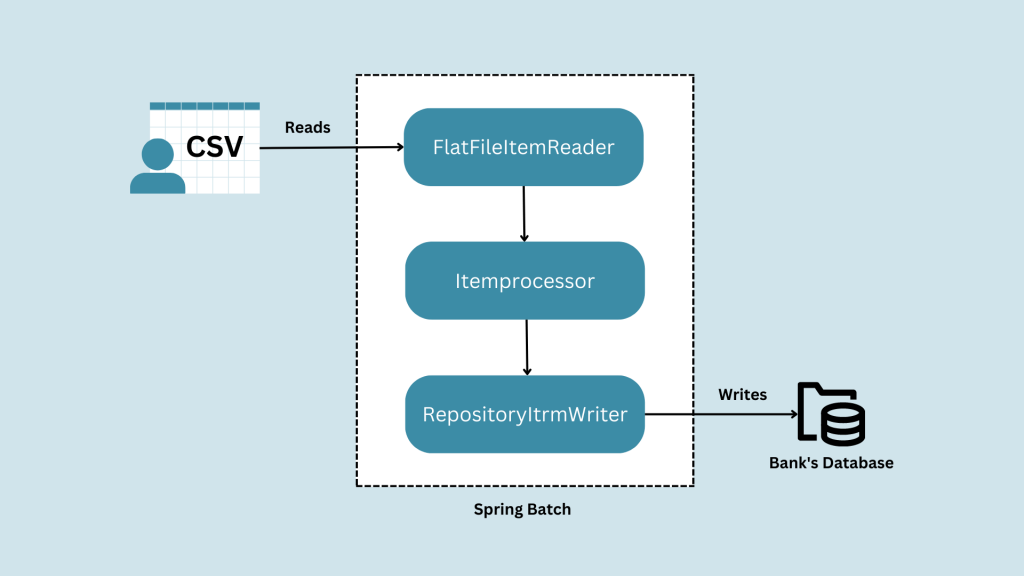
To achieve this, the bank can use Spring Batch to create a batch job that performs the following steps:
1. Read data from the CSV file: Spring Batch provides a FlatFileItemReader that can read data from a CSV file. The bank can use this reader to read the transaction data from the CSV file and convert it into domain objects.
2. Process the data: Once the data is loaded, the bank can use Spring Batch to process the data in bulk, using a range of processors and filters. For example, the bank can use a processor to validate the data, such as checking for missing or invalid values, and a filter to exclude any transactions that do not meet the bank’s criteria.
3. Write the data to the database: After the data has been processed, the bank can use Spring Batch to write the data to the database. Spring Batch provides a RepositoryItemWriter that can write data to a database in batches, which can significantly improve performance.
By using Spring Batch, the bank can automate its data import process, reduce the risk of errors, and improve the efficiency of its operations..
Key concept and Terminology
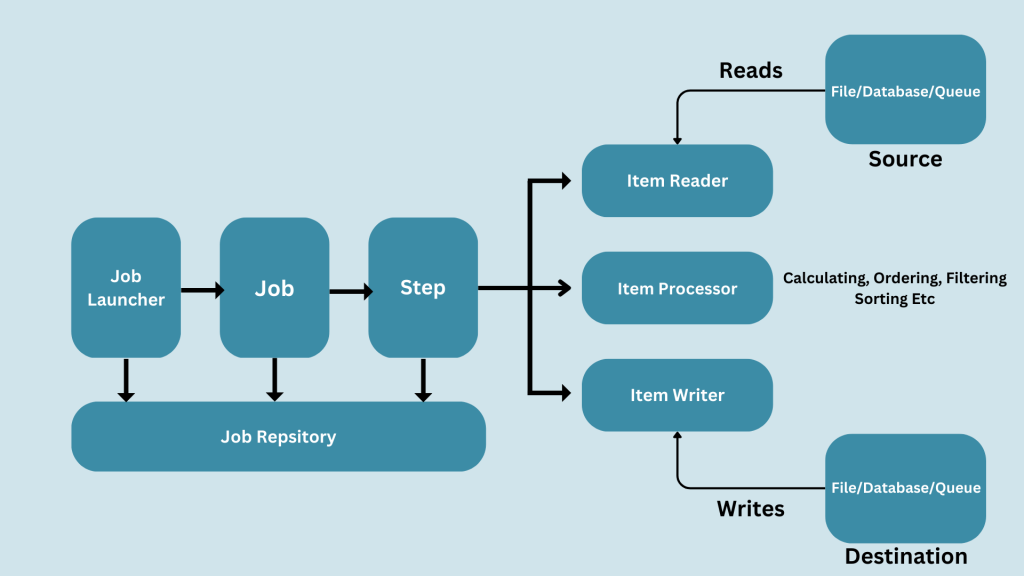
Following are the main terminology used in Spring Batch:-
- Job
- Step
- Item Reader
- Item Processor
- Item Writer
Job
Job represents the work to be completed. It is the object of the java class that implements the
org.springframework.batch.core.Job(I).
Generally, one application contains one Job with one or more Steps (tasks / sub-tasks ). Job creation needs multiple details like name, listener, incrementor, Step etc.
Step
Step object represents one task/subtask of a job. It is the object of the java class that implements the
org.springframework.batch.core.Step(I).
Every step object must link with a ItermReader , a ItermProcessor and ItemWriter Object.
Item Reader
Item Reader is used to read data batch by batch from the source repository. All Item Reader are the implementation of
org.springframework.batch.iterm.
ItemReader<T>. Spring provides many readymade ItermReader like FlatFileItemReader, JmsItemReader, JpaCursorItemReader, JpaPagingItemReader, KafkaItemReader, MongoItemReader etc.
Item Processor
Iterm Processor is given to perform some calculations on the data provided by ItermReader.
All Iterm processors are the implementation of
org.springframework.batch.iterm.ItemProcessor<I,O>.
Generally, we use custom Item processors, for that we need to create a class that implements ItermProcessor<I,O> interface and overwrite process method.<I> of ItemProcessor must match the <T> of ItemReader object and similarly the <O> of item Processor must match with <T> of ItermWriter.
Item Writer
Item Writer is used to write given chunk/batch information to the Destination repository. All Item Writers are the implementation of
org.springframework.batch.iterm.ItemWriter<T>.
Spring provides many readymade ItermWriter like FlatFileItemWriter, HibernateItemWriter,, JdbcBatchItemWriter, JmsItemWriter, JpaItemWriter, KafkaItemWriter, MongoItemWriter, RepositoryItemWriter, etc.
Example application – Reading data from a CSV file and storing it in the Database.
Project Structure
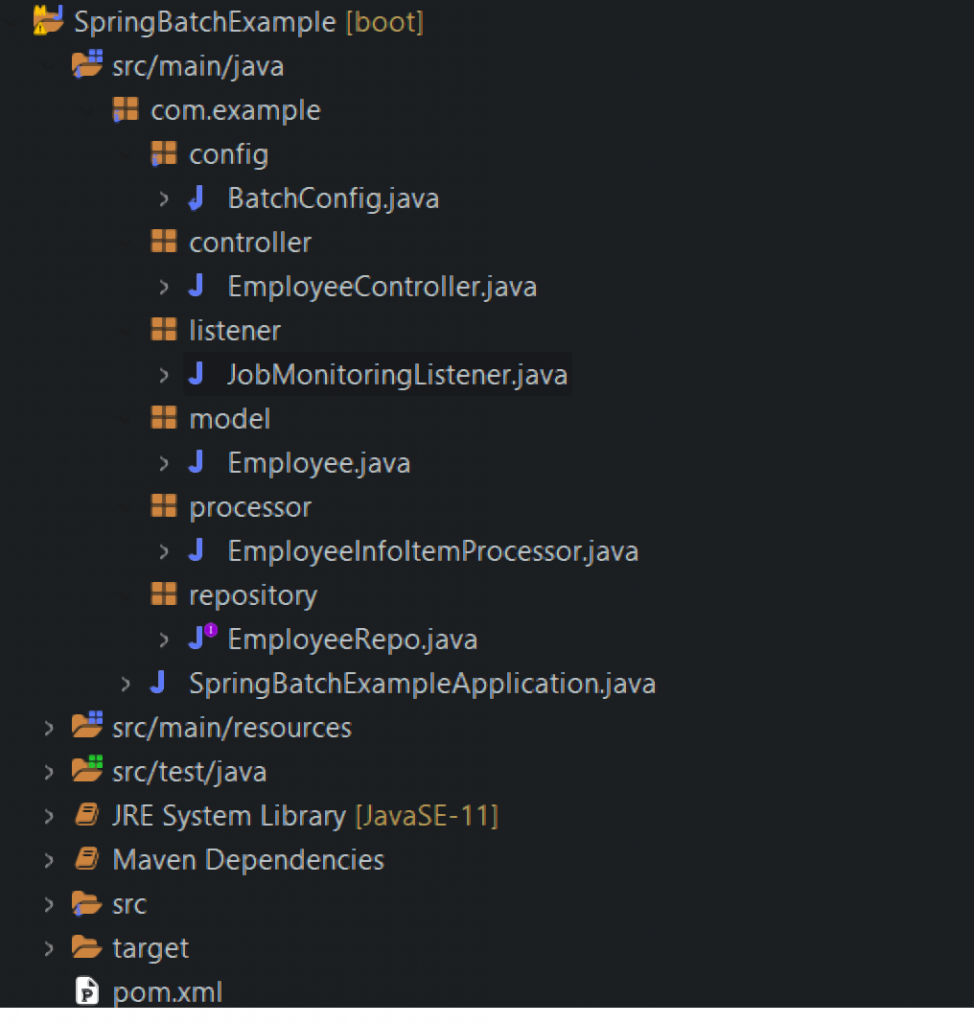
- Create a spring starter project and add the following starter dependencies spring web, Spring Data, JPA, Oracle and Spring batch.
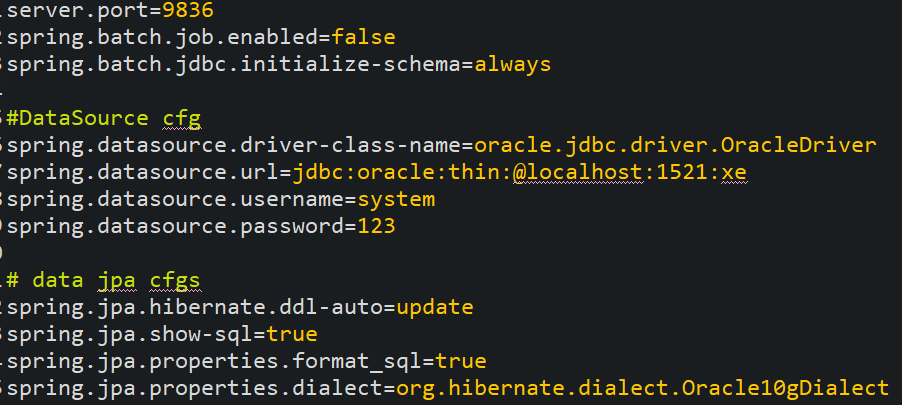
- Add the following entries in the application.properties.
By default, Spring Batch executes all jobs it can find at startup. To change this behavior, disable job execution at startup by adding the following property
spring.batch.job.enabled=false in application.properties.
3. Add emp.csv in the resources folder.
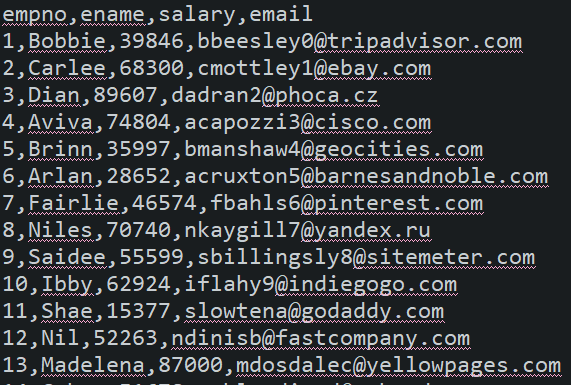
4. Create a model class and repository.
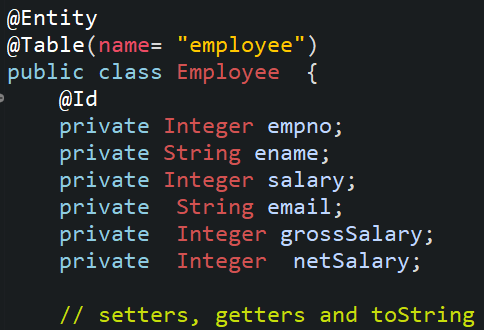

5. Creating a Custom Item processor by implementing ItemProcessor<I, O>.
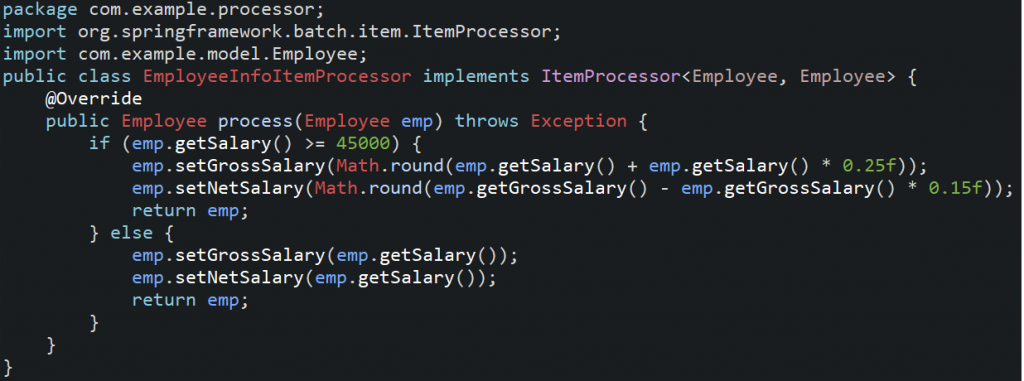
6. Creating a JobMonitoringListener by implementing JobExecutionListener.
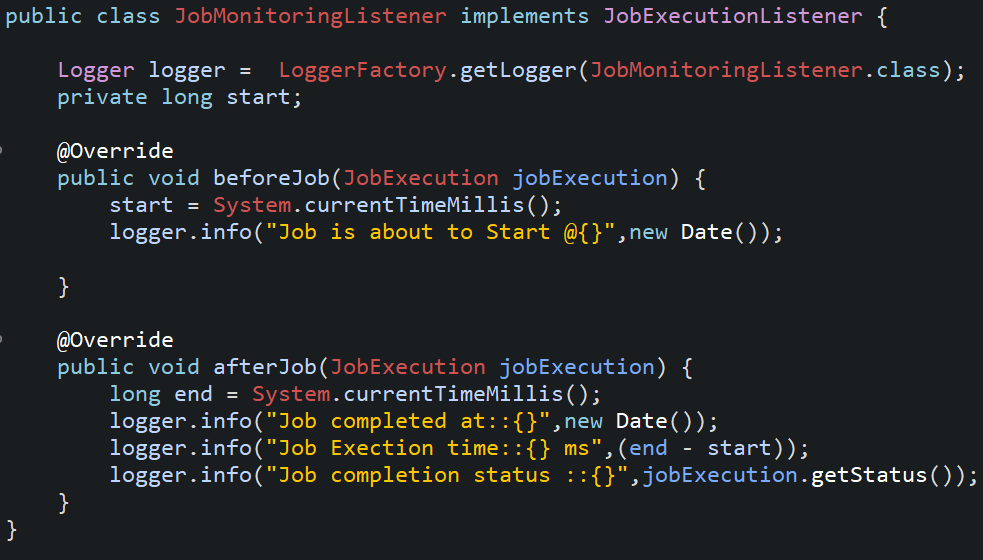
7. Create a configuration class namely BatchConfiguration and annotate with @Configuration and @EnableBatchProcessing and create @Bean methods for ItemReader, ItemWriter, ItemProcessor, Step and Job.

8. Create a bean of ItemReader in the configuration class which will read data from the CSV file.
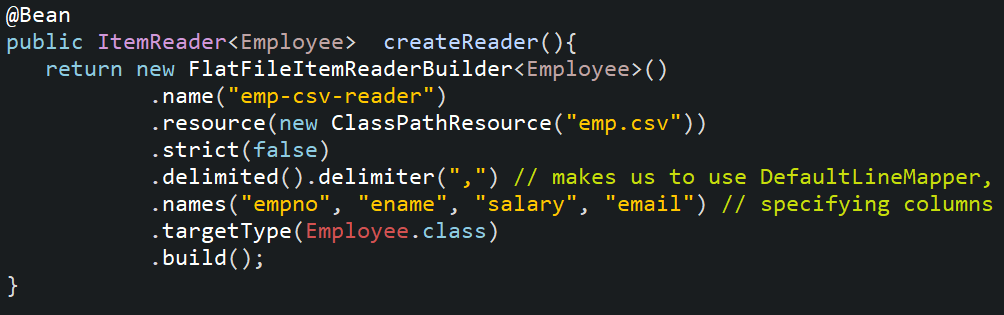 9. Create a bean of ItemWriter in the configuration class which will use EmployeeRepo to write data in the Employee table.
9. Create a bean of ItemWriter in the configuration class which will use EmployeeRepo to write data in the Employee table.
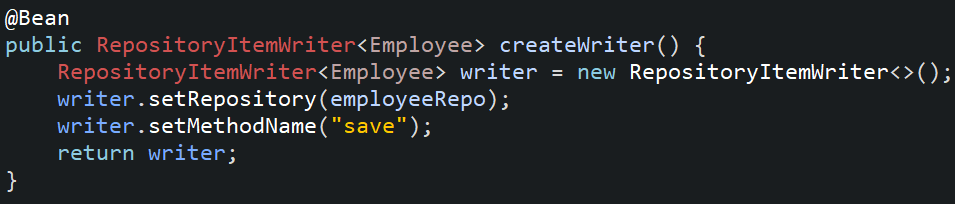
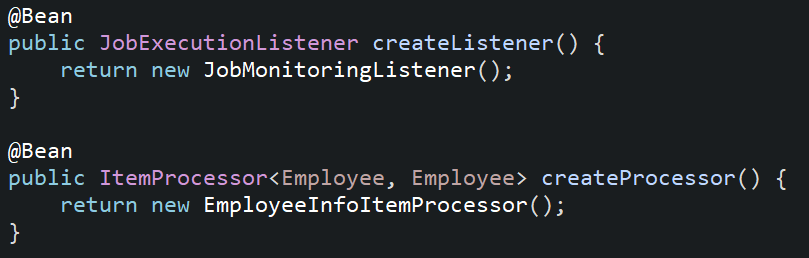
10. Create a bean of ItemProcessor and JobExecutionListener in the configuration class.
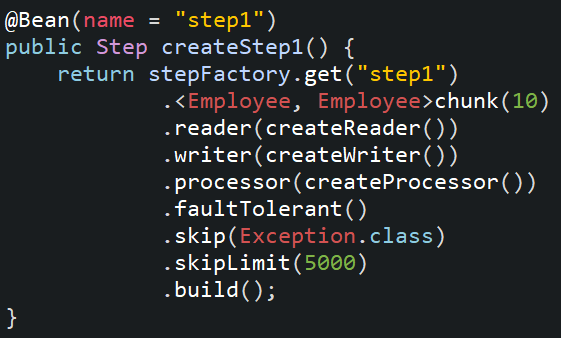
11. Create a bean for Step using StepBuilderFactory and we need to configure item reader, processor and writer information to it.
12. Create a bean for Job using JobBuilderFactory and configure Step, and Listener information.
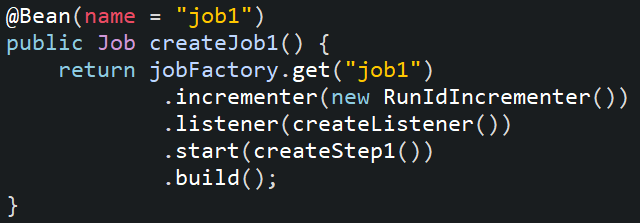
13. Create an EmployeeController class.
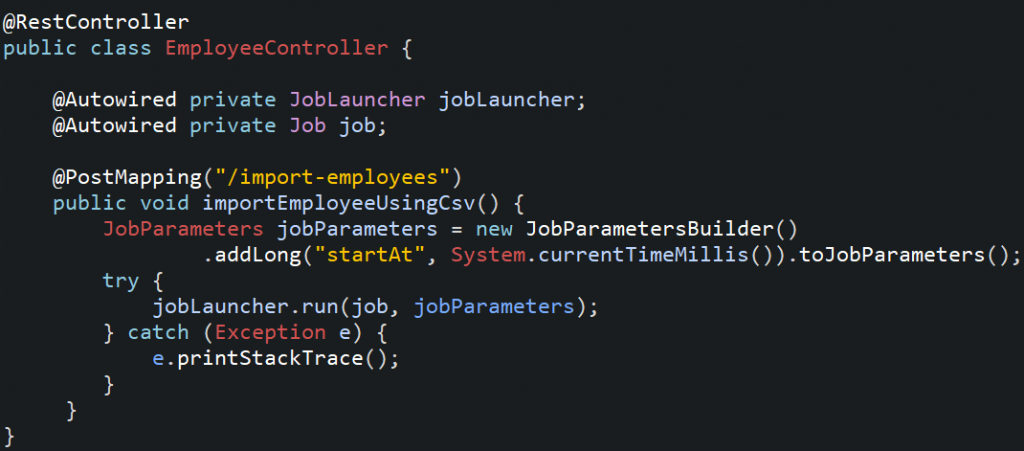
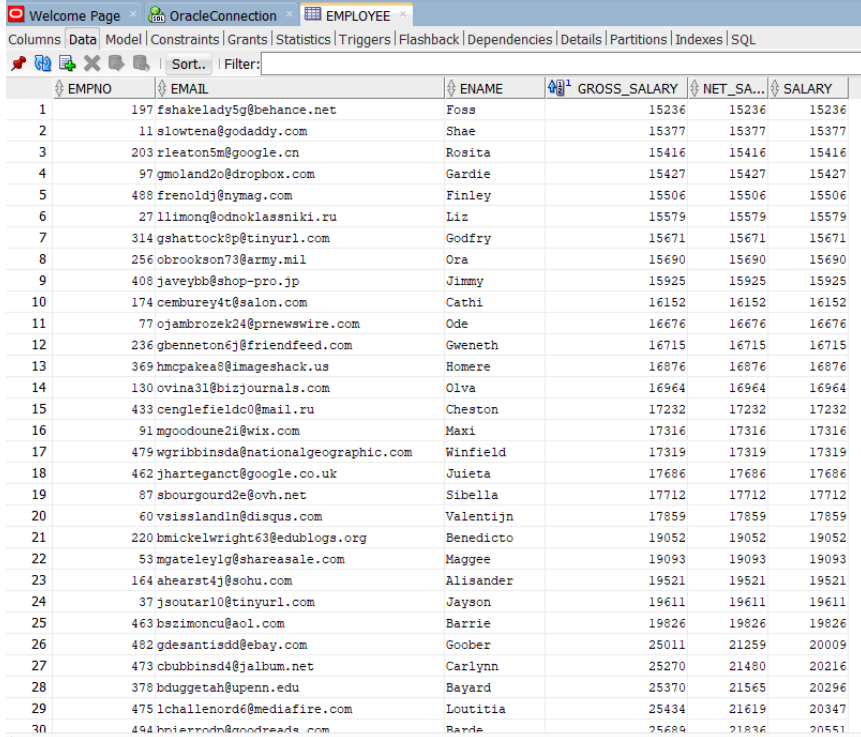
14. Run the application and call import employee API and check the final Final output and logs.

Pros
- Scalable.
- Reusability.
- Robust error handling.
- Parallel Processing.
Cons
- Complex to set up and configure initially.
- Additional dependencies may increase the size of the application.
- Performance overhead due to its additional layers and abstraction.
Conclusion
To summarize, the Spring batch processes data in batches which helps to reduce the load on the system and improve performance. It provides lots of reusable components like Readers and Writers which can be directly used. It also provides a robust error-handling mechanism that ensures that the batch processing jobs can continue even if there are errors. It also provides tools for monitoring and managing batch-processing jobs.









Leave a comment